In small businesses, it is often the case that various data used for administrative tasks are stored in scattered Excel files. While Excel is a great tool for analyzing numerical data, it is not well-suited for searching, aggregating, bulk updating non-numerical data, or joining data from multiple files. One simple solution to this “Excel pain” is to use relational databases instead.
You may think, “Licenses for database software are expensive and only for big companies,” or “We can’t hire people to build and operate databases because it’s complicated and requires special expertise.” However, we can show you that it’s not so difficult to build a small custom database tailored to your needs. Even better, there are open-source solutions to host your database.
What You Need Before Getting Started
Before you get your hands dirty building a database, you need the following:
- A clear objective for your database
- An understanding of (or curiosity to learn) the first, second, and third normal forms of database design
- The ability to draw an Entity Relationship Diagram (ERD)
The second and third items may sound intimidating if you’ve never heard of them. But don’t worry—you don’t need to dive deep. A surface-level understanding is more than enough, and no advanced math is required.
Understanding Relational Databases
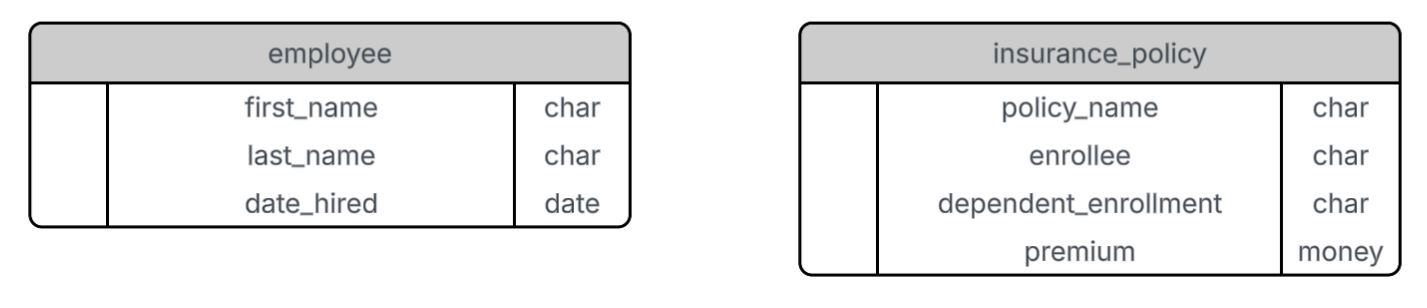
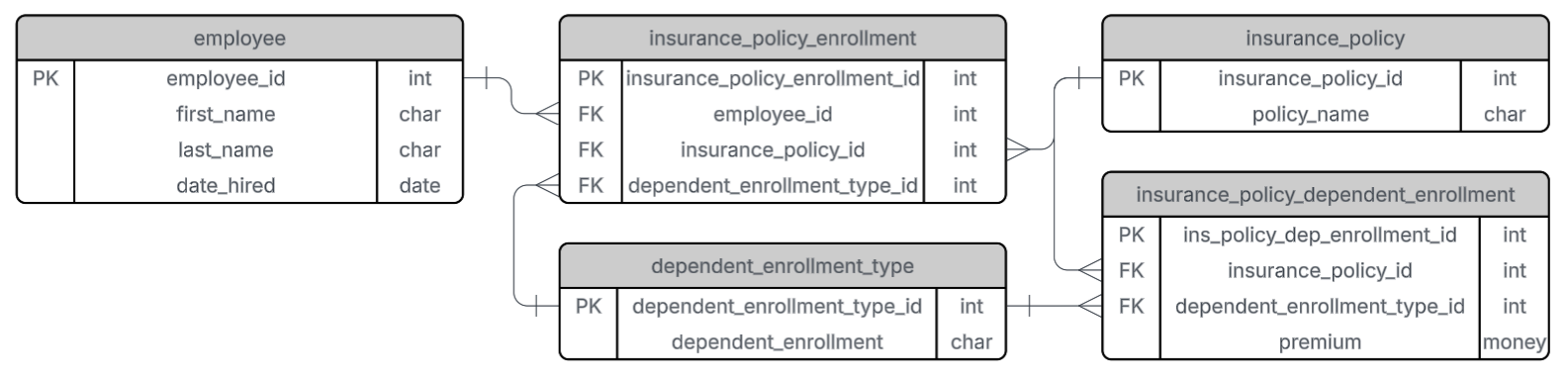
Relational databases are composed of tables organized for specific purposes. Let’s assume we want to build a database to store information on insurance enrollment in your company. We want to be able to look up which employees are enrolled in which insurance policies—and vice versa. To begin, we’ll create two tables: one for employees and one for insurance policies.
Each row in a table represents an entity (e.g., an employee or a policy), and each column represents an attribute (e.g., first name or premium). For example, the employee table includes attributes such as first name, last name, and date hired. The insurance policy table includes attributes such as policy name, enrollee, premium, and dependent enrollment status (e.g., “employee only”, “employee and spouse”, or “family”).
First Normal Form (1NF)
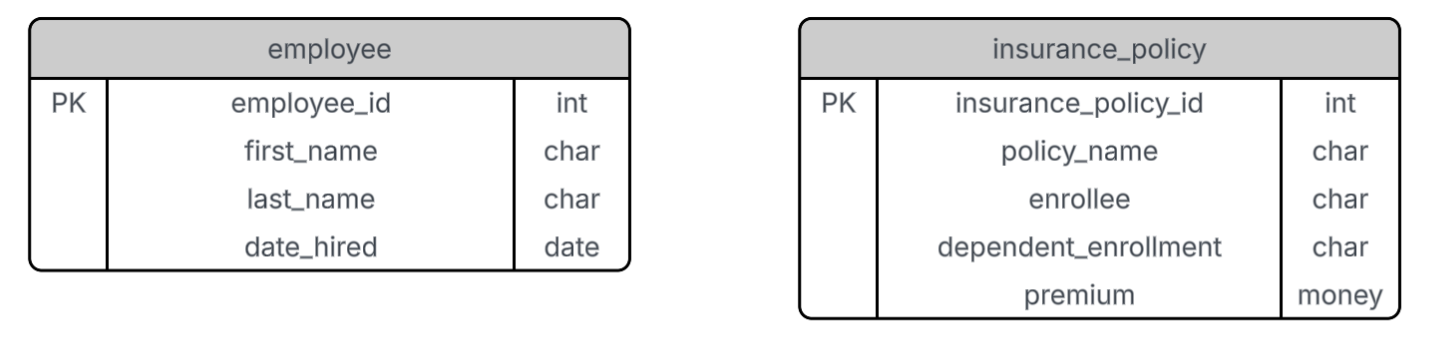
According to the first normal form, every row in a table must be unique. Let’s consider our employee table. If the company has two employees named Ichiro Suzuki who were both hired on the same day, the table would contain duplicate rows—violating 1NF.
The solution is to add an identification number to each table to uniquely identify each row. This is known as a primary key (PK). In our case, we add employee_id and insurance_policy_id as the primary keys of the employee and insurance policy tables, respectively.
Second Normal Form (2NF)
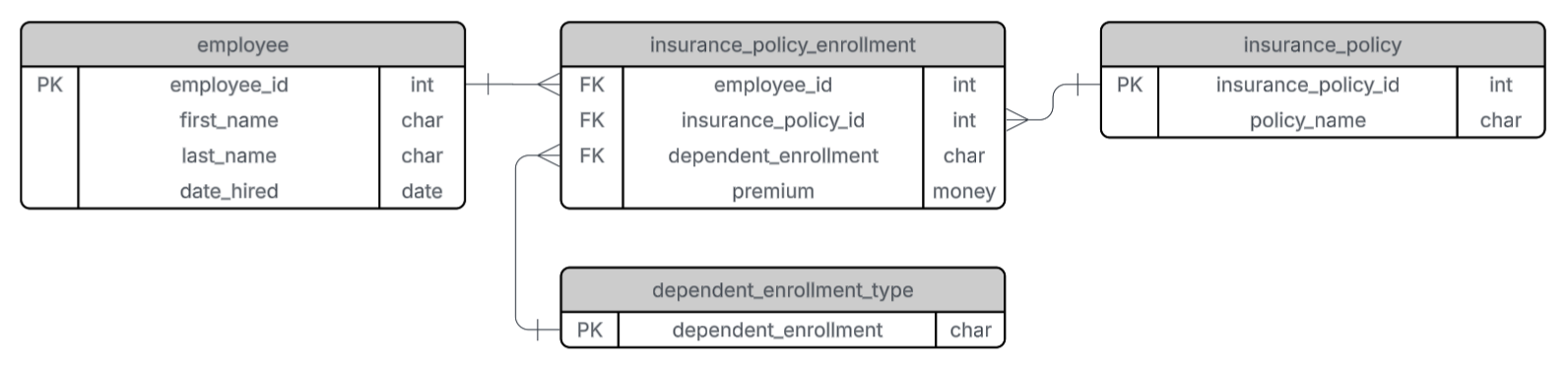
The second normal form requires that each non-primary-key attribute in a table must be fully dependent on the primary key. Our employee table now meets this requirement because all attributes (first_name, last_name, date_hired) depend solely on employee_id.
However, in the insurance policy table, attributes like enrollee, dependent_enrollment, and premium are not determined solely by insurance_policy_id, since each policy can have multiple enrollees. These attributes depend on the relationship between employees and policies.
To address this, we create a new table, insurance_policy_enrollment, with employee_id and insurance_policy_id as foreign keys (FKs). This table represents who is enrolled in which policy.

Next, we move the dependent_enrollment and premium attributes into the insurance_policy_enrollment table, because they depend on both employee_id and insurance_policy_id.

Third Normal Form (3NF)
The third normal form requires that every attribute must depend only on the primary key—not on another non-key attribute.
Our employee table already satisfies this condition. Now, let’s check the insurance_policy_enrollment table. Here, the combination of employee_id and insurance_policy_id is the primary key. But attributes like dependent_enrollment and premium are not strictly dependent on this combination. For example, if an employee has a child, their dependent enrollment status might change, which in turn might affect the premium.
To normalize further, we:
- Create a new table,
dependent_enrollment_type, wheredependent_enrollmentis a key. - Link this to the
insurance_policy_enrollmenttable via a foreign key. - Create another table,
insurance_policy_dependent_enrollment, to map the relationship between insurance policy and dependent enrollment type with associated premiums.
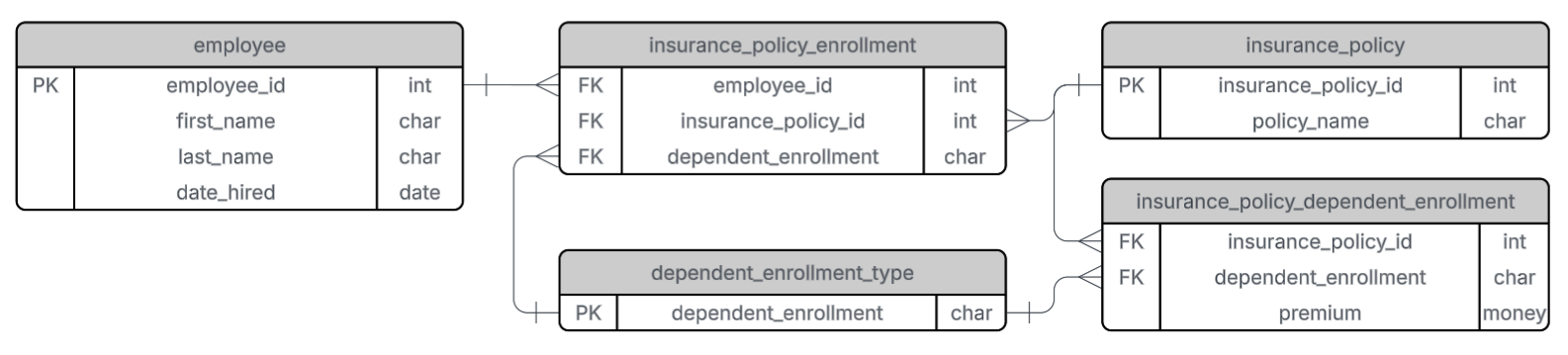
Now all tables meet the requirements of the third normal form.
Final Touch: Add Integer Primary Keys
As a best practice, each table should have an integer primary key for better performance and easier management, especially when using database software such as MySQL or PostgreSQL.
Wrapping Up
Our objective was to build a database that can help you identify:
- Which employees are enrolled in which insurance policies
- Which insurance policies are enrolled by which employees
This is accomplished through queries that join the employee, insurance_policy_enrollment, and insurance_policy tables.
When renewing a contract with your insurance provider, premiums may change. Instead of manually updating every row in a spreadsheet, you only need to update the insurance_policy_dependent_enrollment table—reducing the risk of human error.
Best of all, free and open-source tools like MySQL and PostgreSQL can host your database effortlessly.
Let’s Chat!
Are you interested in building custom databases for your organization but not sure where to start? Let’s talk! Feel free to reach out to us on our LinkedIn page. We’d love to learn about your needs and help you find a solution.