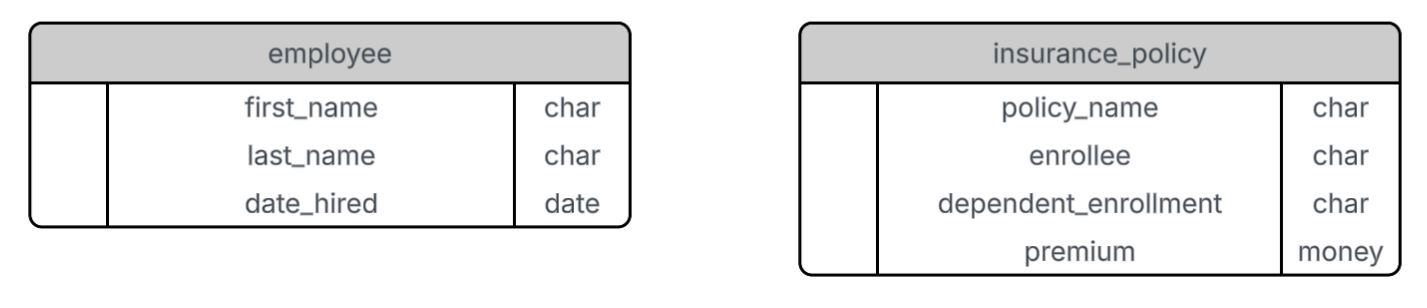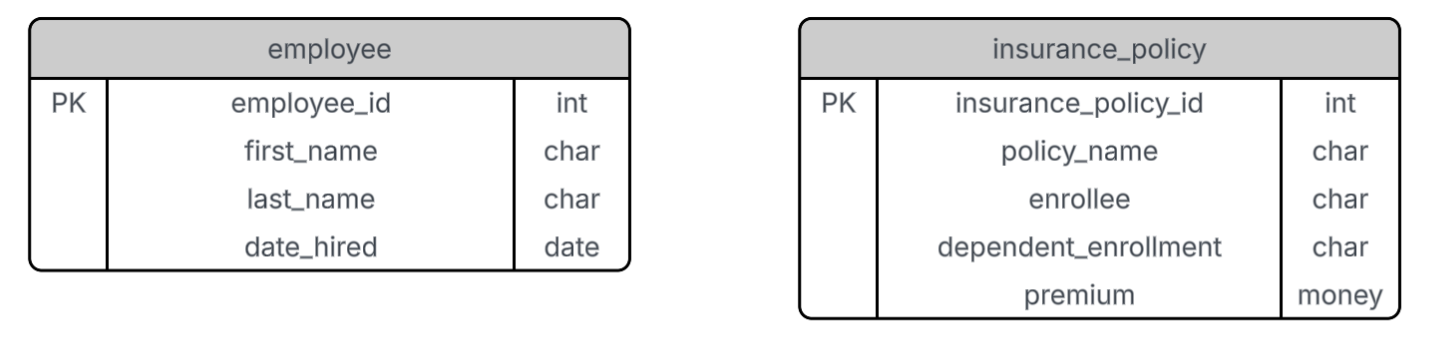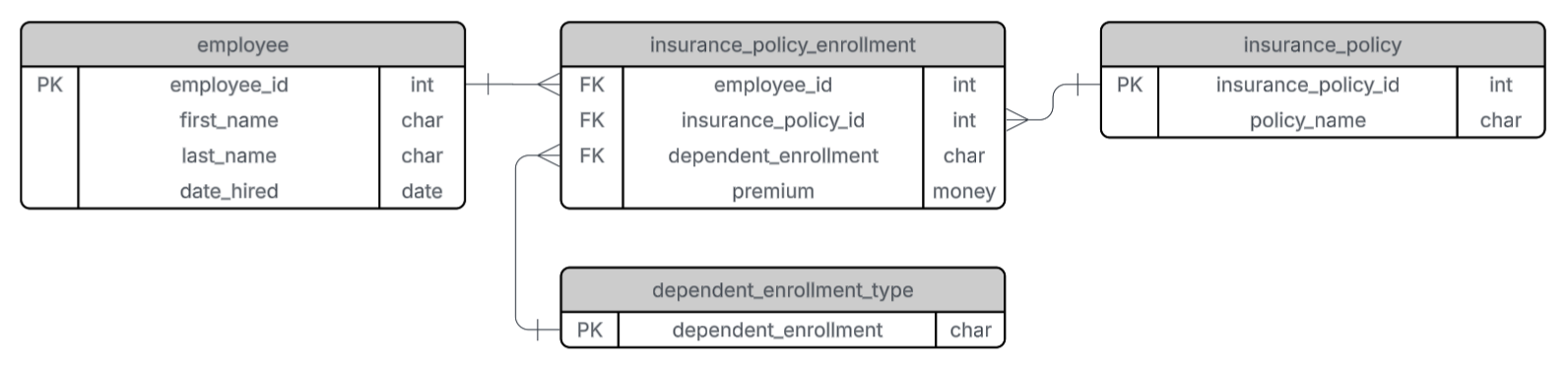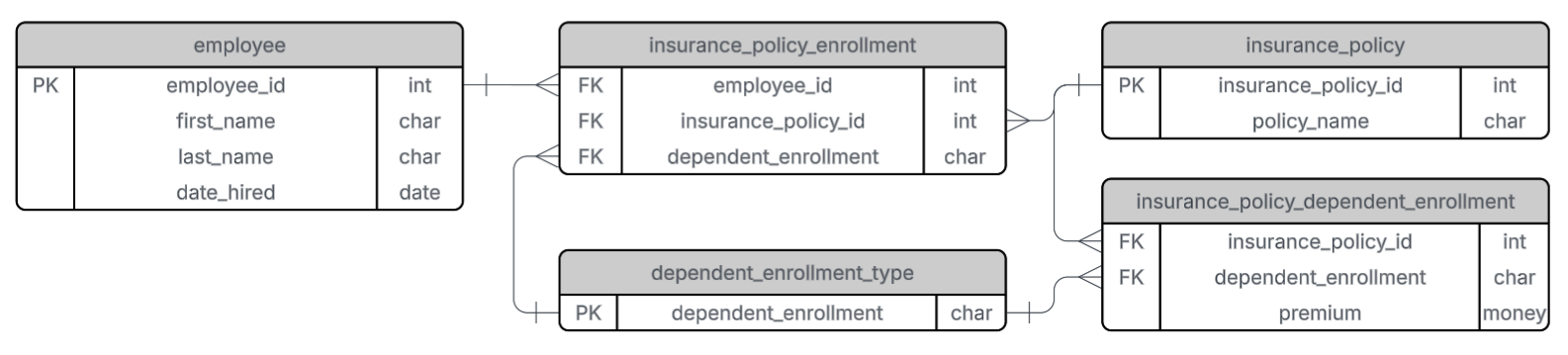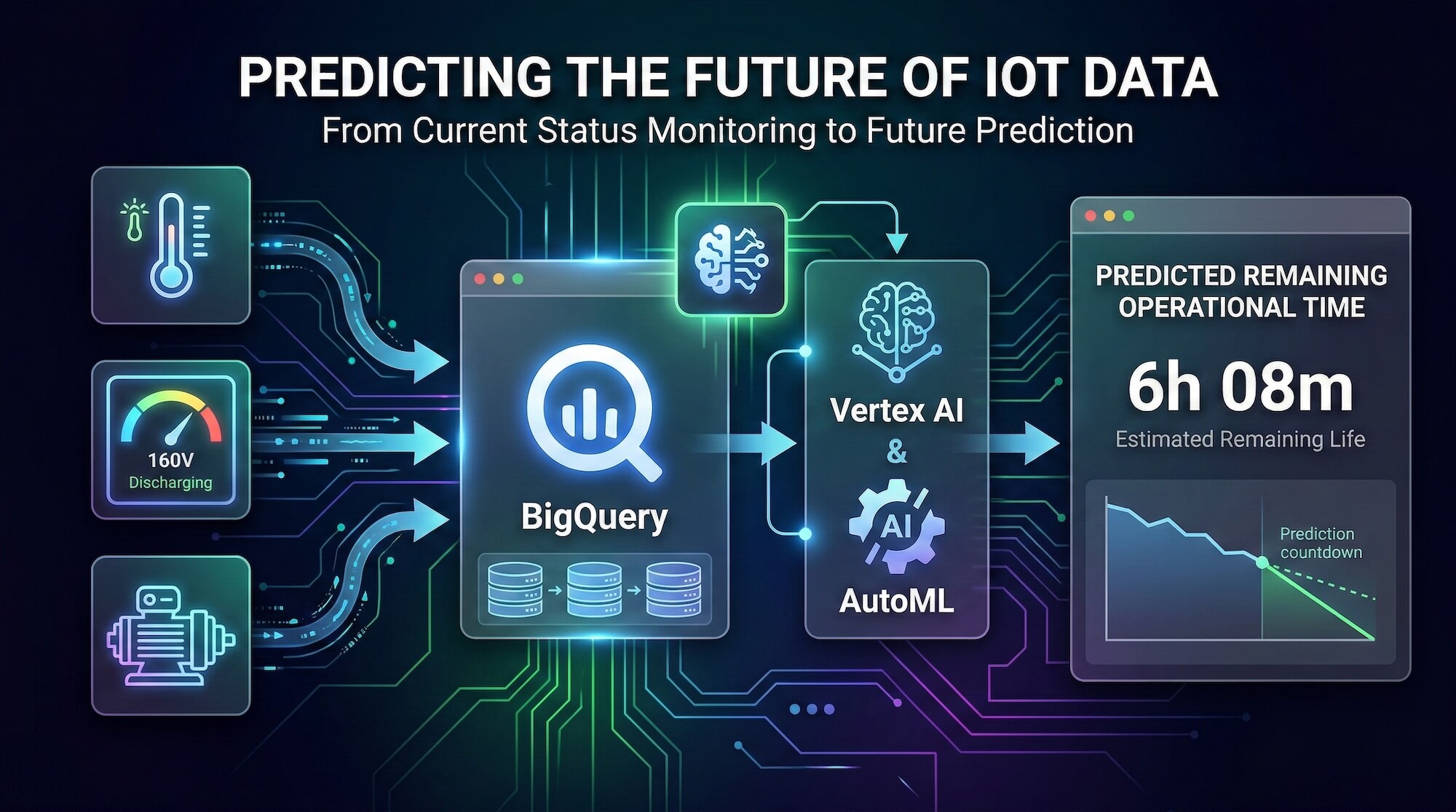
In many businesses today, installing IoT devices and collecting sensor data has become standard practice. Your organization might be gathering thousands of data points—such as voltage, temperature, or load—every single day. While visualizing this historical or real-time data on a dashboard is a valuable first step, it only tells you what is happening right now.
But what if your system could tell you exactly how many hours of operational life your device has left before it stops?
Transitioning from “current status monitoring” to “future prediction” might sound like a complex task reserved for enterprises with massive data science teams. You may think, “Building AI models is too expensive and requires deep mathematical expertise.” However, it is entirely possible to build a custom predictive architecture tailored to your specific hardware. By integrating BigQuery, Vertex AI, and AutoML, you can transform scattered IoT sensor data into a highly accurate, real-time forecasting engine.
The Three Technologies for Prediction
To make your data predictable, you need a system that can securely store historical data, perform feature engineering to find hidden correlations, and process real-time inference requests. Here is how this architecture functions:
1. BigQuery: The Data Ingestion and Preprocessing Foundation
Before you can predict the future, you must establish a baseline from the past. Every second of sensor data your devices generate is securely ingested into BigQuery. As a highly scalable data warehouse, BigQuery stores tens of thousands of historical operation and discharge logs. It acts as the primary data preprocessing environment where raw data is cleaned and structured before being passed to the machine learning engine.
2. Vertex AI & AutoML: Automated Feature Engineering and Regression
Prediction models cannot be built simply by plotting current voltage against time. To predict remaining hardware life accurately, we must analyze historical discharge cycles and identify multi-variable correlations. Inside Vertex AI, AutoML handles this complex process. Rather than manually testing algorithms, AutoML automatically performs feature engineering and selects the optimal regression model based on your BigQuery dataset. It autonomously maps specific voltage drop patterns to their corresponding remaining operational timelines.
3. Real-Time Inference Application
Once AutoML finishes building the model, it is deployed directly within BigQuery using ML.PREDICT. This means your frontend applications can execute predictions using standard SQL queries without needing a separate, dedicated ML hosting server. For instance, in our recent setup, a custom dashboard sends current voltage readings to a backend API. Within milliseconds, the API queries the trained model and returns the predicted remaining operational minutes to the user.

Moving from Reactive to Predictive
You don’t need to write complex algorithms from scratch to benefit from machine learning. By utilizing BigQuery to structure historical data and allowing Vertex AI and AutoML to discover predictive rules autonomously, your business can shift from merely reacting to real-time IoT alerts to proactively planning maintenance and optimizing hardware lifecycles.
At TSG USA Inc., we specialize in turning raw IoT data into actionable intelligence. Whether you need Vertex AI integration or comprehensive Google Cloud architecture, our team is ready to build your next predictive system. Contact us today to get started.